운영체제는 CPU를 프로세스 간에 교환함으로써, 컴퓨터를 보다 생산적으로 만든다.
최신 운영체제에서는 실질적으로 프로세스가 아니라 커널 수준 스레드를 스케줄 한다.
다중 프로그래밍의 목적은 CPU 이용률을 최대화하기 위해 항상 실행 중인 프로세스를 가지게 하는데 있다.
어떤 프로세스가 대기해야 할 경우, 운영체제는 CPU를 그 프로세스로부터 회수해 다른 프로세스에 할당한다.
즉, CPU 이용률을 최대화 하는 것은 다중 프로세서 운영체제 설계의 핵심이 된다.
CPU 스케줄링 시 고려해야할 점
- 어떤 프로세스에게 CPU 리소스를 줘야하는 가?
- CPU를 할당받은 프로세스가 얼마의 시간동안 CPU를 사용해야 하는 가?
- CPU Burst : CPU를 할당받아 실행하는 작업
- I/O Burst : 입출력 작업
CPU 스케줄링 목표
"모든 프로세스가 공평하게 작업할 수 있도록 하는 것"
- 리소스 사용률 : CPU, I/O 디바이스 사용률을 높이는 것.
- 오버헤드 최소화 : 스케줄링을 하기 위한 계산이 너무 복잡하거나 컨텍스트 스위칭 등의 오버헤드를 줄이는 것.
- 공평성 : 모든 프로세스가 CPU를 공평하게 할당 받아야함.
- 처리량 : 같은 시간 내에 더 많은 처리를 하는 것.
- 대기시간 : 대기 시간이 짧은 것.
- 응답시간 : 응답시간이 짧은 것.
하지만 이 모든 목표들을 최고의 수준으로 유지하기 힘듦
- 처리량, 응답시간의 목표를 같이 달성할 수 없음
- 처리량을 높이려면, 하나의 프로세스에 CPU를 오래 할당해야 함
- 응답시간을 줄이려면 여러 프로세스에 골고루 CPU를 할당해야 함
- 사용자가 사용하는 시스템에 따라 목표를 다르게 설정함
- 터치스크린의 경우 응답시간을 짧게
- 과학 계산의 경우 처리량을 많게
- 일반사용자의 경우, 특정한 목적이 없다면 목표를 밸런스 있게 유지하는 것이 목표.
CPU 스케줄링 알고리즘
1. FIFO(First In First Out)
- 먼저 들어온 프로세스가 끝나야 다음 프로세스가 실행될 수 있음
- 마트 계산대로 생각하면 됨
장점
- 단순하고 직관적
단점
- 실행시간이 짧고 늦게 도착한 프로세스가 실행시간이 길고 빨리 도착한 프로세스의 작업을 기다려야함.
- I/O 작업의 경우 CPU 사용률이 떨어짐.
스케줄링의 성능 : 평균 대기 시간으로 평가함
- 평균 대기 시간 : 프로세스가 모두 실행되기까지 대기시간의 평균
Case 1. 프로세스1(25초) / 프로세스2(5초) / 프로세스3(4초)
→ 평균 대기 시간 : (0초 + 25초 + 30초) / 3 = 18.3초
Case 2. 프로세스3(4초) / 프로세스2(5초) 프로세스1(25초)
→ 평균 대기 시간 : (0초 + 4초 + 9초) / 3 = 4.3초
Burst Time(실행시간)에 따라 성능이 크게 차이가 남.
현대 운영체제에서 잘 쓰이지 않고. 일괄처리 시스템에 쓰임.
2. SJF(Shortest Job First)
- 실행시간(Burst Time) 이 가장 짧은 프로세스 먼저 실행
문제점
- 어떤 프로세스가 얼마나 실행될 지 예측하기 힘들다 → 종료시간 예측은 거의 불가능
- 실행시간이 긴 프로세스는 오랫동안 실행되지 않을 수 있음
→ 이러한 문제점 때문에 사용되지 않음.
3. RR(Round Robin)
FIFO 의 단점 해결 → 일정시간 동안 프로세스를 할당, 할당시간이 지나면 강제로 다른 프로세스에게 할당 후 큐의 맨 뒤로 감
- 타임 슬라이스(=타임퀀텀) : 프로세스에게 할당하는 일정 시간
성능
- 타임 슬라이스 : 10s 일 경우
Case 1. 프로세스1(25초) / 프로세스2(4초) / 프로세스3(10초)
→ 평균 대기 시간 : (0초 + 10초 + 14초 + 14초 + 0초) / 3 = 12.67초
→ 평균 대기 시간(FIFO) : 18초
RR 과 FIFO 의 알고리즘 평균 대기 시간이 같더라도 RR는 Context Switching 시간이 있기 때문에 FIFO가 더 효율적임
RR 은 타임 슬라이스의 값에 따라 크게 달라짐.
- 타임 슬라이스가 큰 경우 →무한대 → FIFO 알고리즘이 됨
- 타임 슬라이스가 작은 경우 → 1ms → 오버헤드가 너무 크다(문맥교환 시간이 많이 걸린다)
OS별 타임 슬라이스
- Windows : 20ms
- Unix : 100ms
4. MLFQ(Multi Level Feedback Queue)
- 가장 일반적으로 사용되는 알고리즘
- RR의 업그레이드 된 알고리즘
CPU Bound Process : CPU 연산을 많이하는 프로세스
→ CPU 사용률, 처리량이 가장 중요
I/O Bound Process : I/O 연산을 많이하는 프로세스
→ 응답속도가 가장 중요

Case1. 타임슬라이스 100초
→ CPU 사용률 : 100%
→ I/O 사용률 : 10%
Case2. 타임슬라이스 1초
→ CPU 사용률 : 100%
→ I/O 사용률 : 90%
타임 슬라이스가 작은 경우에 성능이 더 좋음. 하지만 하나의 프로세스가 손해를 보는 구조임.
P1은 문맥교환 때문에 오버헤드 발생 → 이를 보완한 것이 MLFQ
타임 슬라이스를 기본적으로 작게 할당하지만 CPU Bound Process 에게는 타임슬라이스를 크게 줌.
CPU Bound Process와 I/O Bound Process 의 구분은 어떻게?
- 프로세스가 실행하다가 스스로 CPU를 반납하면 CPU 사용률이 적은 것 → I/O Bound Process 일 가능성이 높음
- CPU를 사용하는 프로세스가 실행하다가 타임슬라이스 크기를 오버해서 CPU 스케줄러에 의해 강제로 CPU를 뺏기는 상황이면 CPU 사용률이 높은 것 → CPU Bound Process
우선순위 큐를 여러개 준비해두고, 우선순위가 낮을 수록 타임슬라이스 크기가 커짐.
P1이 사용하다가 스케줄러에 의해 CPU를 강제로 뺏기는 경우에는 우선순위가 밀려남 (=타임 슬라이스가 조금 더 커짐)
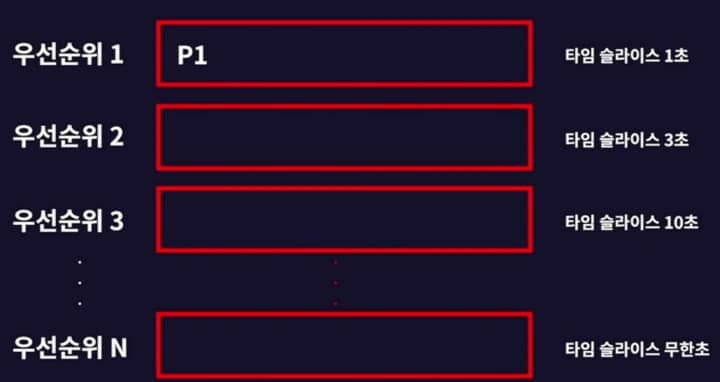
- 더 많은 알고리즘 : HRN, SRT, MLQ, Priorty
- 하지만 MLFQ 가 가장 주류임
출처
- https://imbf.github.io/computer-science(cs)/2020/10/18/CPU-Scheduling.html
- https://inf.run/5tsi
'IT > OS' 카테고리의 다른 글
| [Windows] 윈도우 원격 데스크톱 포트 변경 방법(How to Change the Listening Port for Remote Desktop) (1) | 2022.01.24 |
|---|---|
| [OS] 프로세스 동기화(세마포어, 모니터, 임계구역) (2) | 2022.01.20 |
| [OS] 좀비 프로세스(Zombie Process)란? 부모프로세스와 자식프로세스 (0) | 2022.01.15 |
| [OS] 멀티프로그래밍과 멀티프로세싱(Feat. PCB, Context Switching) (0) | 2022.01.15 |
| [OS] 프로그램과 프로세스의 차이, 컴파일(Compile), CPU 구성요소 (2) | 2022.01.12 |




댓글